Designing Data Intensive Applications Notes: Ch.6 Partitioning
Mohamed Kassem | November 04, 2023

Continuing our series for “Designing Data-Intensive Applications” book.
In this article, we will walkthrough the second chapter of this book Chapter.6 Partitioning.
Table of Content
Partitions are defined in such a way that each pie of data (record, document) belongs to one partition.
Each partition is a small database of its own, however we need to support operations that touch multiple partitions at the same time. The main reason for Replication is high availability and reduce latency while the main reason for partitioning scalability.
Usually we combine replication and partitioning: each node acts as leader for some partitions and follower for other partitions.
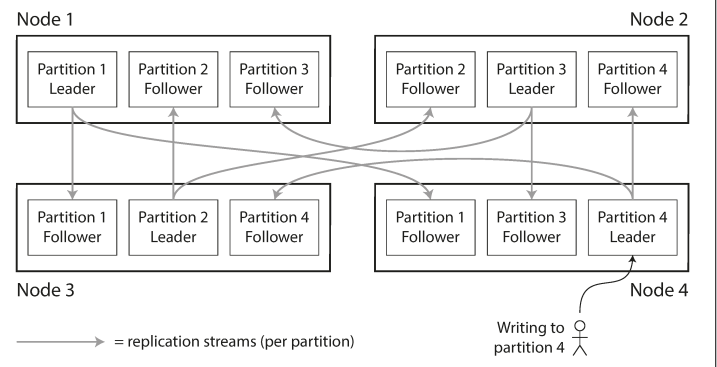
For 10 replicas theoretically speaking, we expect to get
- 10x Storage
- 10x Read and write throughput
How do you partitioning data ?
Partitioning of Key-Value Data
The goal of partitioning is to spread data evenly across nodes, and more importantly to avoid having skewed partitions with most of the load (called hot spots).
There are two main ways of partitioning keys:
Partitioning by key range
By sorting the keys we have and assigning a continuous range of keys (Like encyclopedia, partition is from A to B, other from D to F)
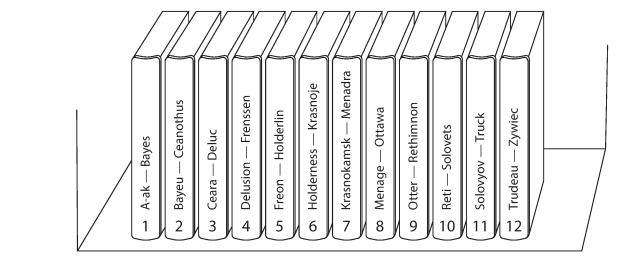
The problem with this approach is the partitioning is not always fair and this lead that some partitions will have much bigger data than others (this called partition boundaries). This approach is used in HBase and RethinkDB, and MongoDB before version 2.4.
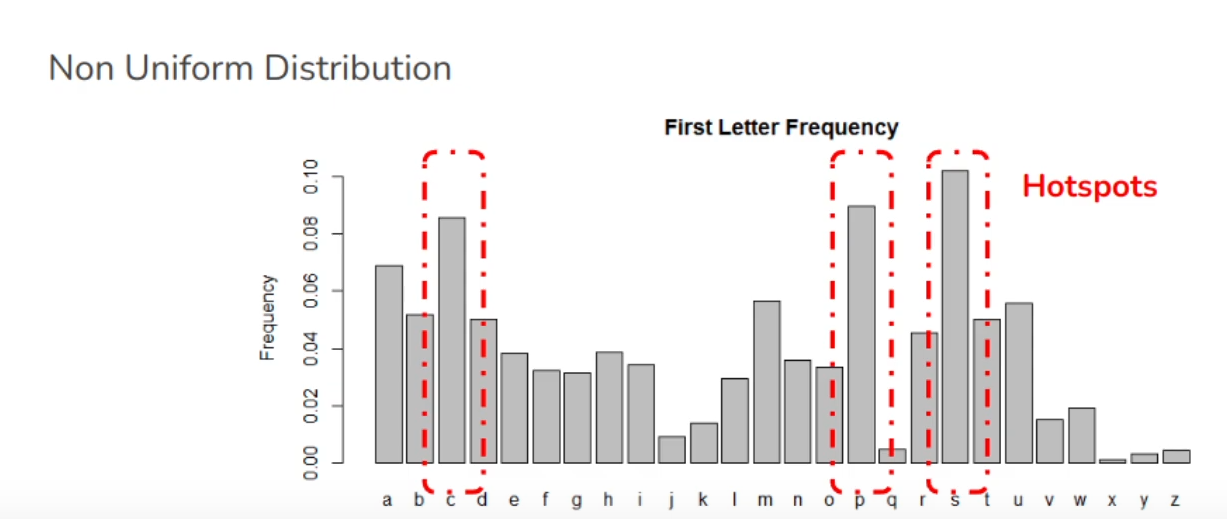
Partitioning by Hash of Key
To fix the issue of skewed data and makes it uniformly distributed. Thtats by using a non-cryptographic hash function (eg. MD5 used in Cassandra and MongoDB and Voldemort uses the Fowler-Noll-Vo hash function).
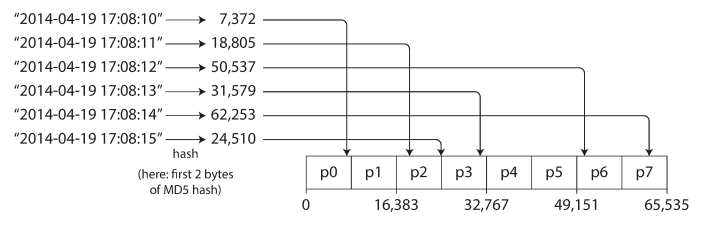
The issue with this approach is cannot do range query (from - to) from the same partition.
In MongoDB, if you have enabled hash-based sharding mode, any range query has to be sent to all partitions. Range queries on the primary key are not supported by Riak, Couchbase, or Voldemort
Cassandra find a compromise approach to achieve rang-query on hash key by using compound/composite primary key. also called “one-to-many actions” we will partition based on one which has many action/updates
Only the first part of that key is hashed to determine the partition (on the example: zipcode or username), but the other columns are used as a concatenated index for sorting the data.
for example the following query key = zipcode, username, activitytimestamp
zipcode = "2011201" AND
user_name like "M%" AND
activity_timestamp > "2023-01-01"Another example, on a social media site, one user may post many updates. If the primary key for updates is chosen to be (userid, updatetimestamp), then you can efficiently retrieve all updates made by a particular user within some time interval, sorted by timestamp. Different users may be stored on different partitions, but within each user, the updates are stored ordered by timestamp on a single partition.
One problem still is when most reads and writes are for the same key (causing hotspot and skewed partitions). for example on a social media site, a celebrity user with millions of followers may cause a storm of activity when they do something.
This usually left for the application to handle this skew, typically by assigning random bytes at the beginning/end of this key to scatter it across all the replicas, however, this requires extra bookkeeping/work, as well as requests to all the replicas when reading.
Partitioning and Secondary Indexes
Partitioning Secondary Indexes by Document (Local Index)
In this indexing approach, each partition maintains its own secondary indexes (stores locally with the partition), covering only the documents in that partition.
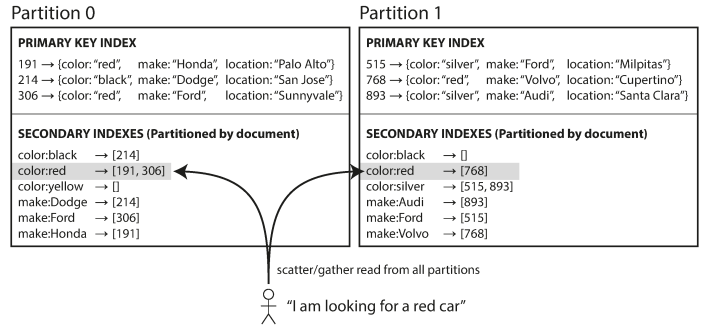
Whenever you need to write to the database (to add, remove, or update a document) you only need to deal with the partition that contains the document ID that you are writing. (Good on write performance).
The issue with this approach is the index duplication, in the above example, if you want to search for red cars, you need to send the query to all partitions, and combine all the results you get back (this technique called scatter/gather from all partitions) (Not very good on read performance)
Nevertheless, it is widely used: MongoDB, Riak, Cassandra, Elasticsearch, SolrCloud, and VoltDB.
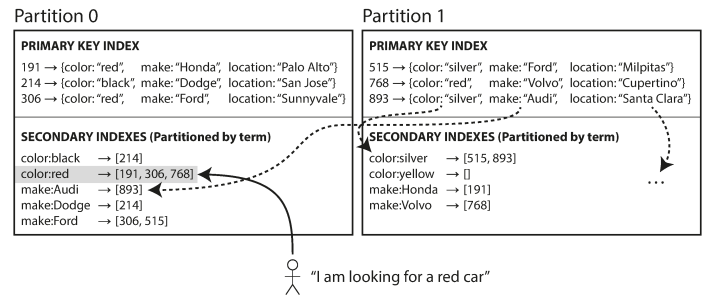
Partitioning Secondary Indexes by Term (Global Index)
Another option is to have a global secondary index which can also be partitioned, but using term/topic instead of document. Every partition would keep a secondary index of some of these terms (range of terms),
This makes reads more efficient, rather than doing scatter/gather in all partitions, but writes are slower and complicated. However, in practice updates to global secondary indexes are asynchronous and very fast.
Rebalancing Partitions
Why I need rebalancing partitions? Over the time, things change in a database:
- The queries/requests throughput increases ⇒ Add CPUs
- The storage size increases ⇒ Add disks & RAM
- A machine fails ⇒ Failover machines
Hash mod N (worst one)
This way we get hash of key and mod it by N nodes, since the result will be always from 0 to N. For example hash(key) mod 10 would return a number between 0 and 9 (if we write the hash as a decimal number, the hash mod 10 would be the last digit). If we have 10 nodes, numbered 0 to 9.
The problem with this approach is N nodes changes most of the keys will need to be moved from one node to another. For example, say hash(key) = 123456. If you initially have 10 nodes, that key starts out on node 6 (because 123456 mod 10 = 6). When you grow to 11 nodes, the key needs to move to node 3 (123456 mod 11 = 3), and when you grow to 12 nodes, it needs to move to node 0 (123456 mod 12 = 0).
Fixed number of partitions (over paritioning)
Create many more partitions than nodes and assign several partitions to each one.
Number of partitions does not change if the nodes number got changed (unlike hash mod N).
For example, a database running on a cluster of 10 nodes may be split into 1,000 partitions from the outset so that approximately 100 partitions are assigned to each node.
So, if we add new node, a few partitions are steal, so each node will handle 1000/11 = 90 partitions
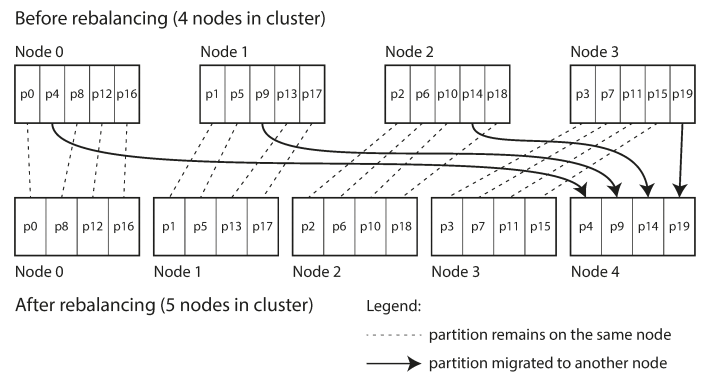
This approach to rebalancing is used in Riak, Elasticsearch, Couchbase, and Voldemor.
The issue is with this approach is not suitable when data size is unpredictable with fixed partitions number, partition management overhead, large partition slow down the rebalance.
Dynamic Partitioning with Data Size (B Tree like)
When a partition grows to exceed some configured size, it is split into two partitions so that approximately when shrinks below a configured size, we merge it with an adjacent partition.
So this approach is adaptive partitions that grows with data automatically.
the issue with approach
- Initial partitioning, if you use 10 nodes, you will wait until initial partition to grow up to fit all these nodes dynamically.
- Cannot work with key-range partitions, since growing up and shrinks is dynamic (randomly). It works well with hash-partitioned data. MongoDB since version 2.4 supports both key-range and hash partitioning, and it splits partitions dynamically in either case.
Partitioning proportionally to nodes count
Like Fixed number of partitions but make the number of partition proportionally to nodes count to have a fixed number of partitions per node. for example if I have 1000 partition for 10 nodes, if i crease the nodes to 20, then 2000 partitions. in Cassandra, 256 partitions per node by default
It can be a good thing to have a human in the loop for rebalancing.
Request Routing
when a client wants to make a request, how does it know which node to connect to? which IP address and port number do I need to connect to?
This general problem need service discovery which isn’t limited to just database
there are a few different approaches to this problem
- Allow clients to contact any node (e.g., via a round-robin load balancer). if that node owns the partition then handle it. otherwise, forward to another node
- Send all requests from clients to a routing tier first (partition-aware load balancer).
- Require that clients be aware of the partitioning and the assignment of partitions to nodes
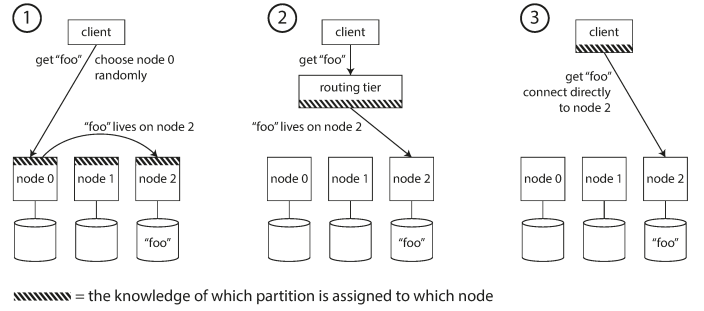
Apache ZooKeeper is handle this routing and coordination to keep track of this cluster metadata.
ZooKeeper maintains the authoritative mapping of partitions to nodes. Other actors, such as the routing tier or the partitioning-aware client, can subscribe to this information in ZooKeeper. Whenever a partition changes ownership, or a node is added or removed, ZooKeeper notifies the routing tier so that it can keep its routing information up to date.
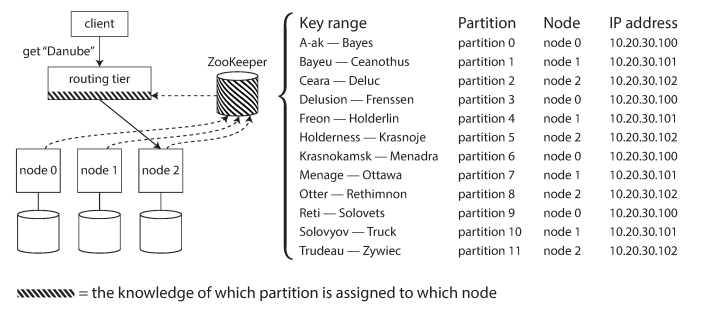
LinkedIn’s Espresso, HBase, SolrCloud, and Kafka also use ZooKeeper to track partition assignment. MongoDB has a similar architecture, but it relies on its own config server implementation and mongos daemons as the routing tier.
Cassandra and Riak take a different approach: they use a gossip protocol among the nodes to disseminate any changes in cluster state.
Couchbase does not rebalance automatically. Normally it is configured with a routing tier called moxi.