Designing Data Intensive Applications Notes: Ch.5 Replication
Mohamed Kassem | November 02, 2023

Continuing our series for “Designing Data-Intensive Applications” book.
In this article, we will walkthrough the second chapter of this book Chapter.5 Replication.
Table of content
- Leaders and Followers
- Synchronous vs Asynchronous Replication
- Setting Up New Followers
-
How does replication work (Implementation of replication log)
Replication means keeping a copy of the same data on multiple machines that are connected via a network. Why we do replication?
- To keep data geographically close to your users (and thus reduce latency)
- Increase availability
- To scale out the number of machines that can serve read queries (Increase read throughput)
Leaders and Followers
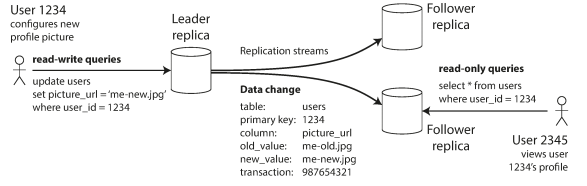
leader-based replication (or master-slave) is designated the leader when clients want to write to the database, they must send their requests to the leader, first writes the new data into its local storage, then sends the data change to all of its followers.
When a client wants to read from the database, it can query either the leader or any of the followers. However, writes are only accepted on the leader.
This mode is a built-in feature in relational databases such as PostgreSQL, MySQL, Oracle, and SQL Server. Also, for non-relational databases such as MongoDB, RethinkDB, Espresso. Also in message brokers such as Kafka, RabbitMQ.
Synchronous vs Asynchronous Replication
Synchronous replication mean that we will wait until all followers get updated, then responded to the user.
Asynchronous replication mean that we will response immediately to the user, and after that in the background we update the followers.
The following example shows Leader-based replication with one synchronous and one asynchronous follower.
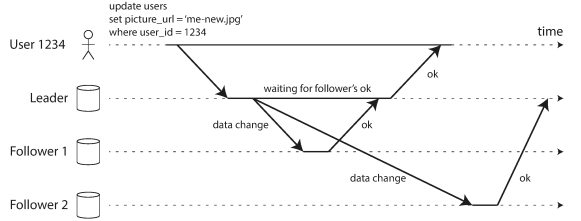
Follower 1 is synchronous: the leader waits until follower 1 has confirmed that it received the write before reporting success to the user.
Follower 2 is asynchronous: the leader sends the message, but doesn’t wait for a response from the follower.
The advantage of synchronous
- The follower is guaranteed to have an up-to-date copy.
- If the leader suddenly fails, we can be sure that the data is still available on the follower.
The disadvantage of synchronous
- The leader must block all writes and wait until the synchronous replica is available again.
For the above reason, the best practice you make one follow synchronously and the other is asynchronous (this approach is sometimes called semi-synchronous).
Setting Up New Followers
How do you ensure that the new follower has an accurate copy of the leader’s data? copying data files from one node to another will not work as there is constantly writing to DB.
To set up new followers without downtime
- Take a consistent snapshot of the leader’s database at some point in time.
- Copy the snapshot to the new follower node.
- The follower connects to the leader and requests all the data changes that have happened since the snapshot was taken.
Handling Node Outages
Follower failure: Catch-up recovery
On its local disk, each follower keeps a log or snapshot of the data changes it has received from the leader.
The follower can recover quite easily: from its log, it knows the last transaction that was processed before the fault occurred. Thus, the follower can connect to the leader and request all the data changes that occurred during the time when the follower was disconnected.
Leader failure: Failover
If the leader crashes, one of the following needs to be promoted to be the new leader, and clients need to be reconfigured to send their writes to the new leader, and the other followers need to start consuming data changes from the new leader. This process is called failover.
Failover can be happened manually (by the administrator) or automatically by the following steps:
- Determining that the leader has failed (based on node respond timeout)
- Choosing a new leader through the election process or by the most updated data node.
- Reconfiguring the system to use the new leader
Automatic failover may be going wrong
- If asynchronous replication is used, the new leader may not have received all the writes from the old leader before it failed.
- Promoted update followers can cause conflicts and discarding some data
Thus, some operations teams prefer to perform failovers manually.
How does replication work (Implementation of replication log)
Statement-based replication
The leader logs every write request (statement) and sends that statement (Insert, Update, Delete) to its followers and then execute this SQL query. This method is used in MySQL.
Disadvantages of this approach
- Inconsistent data when use nondeterministic function, such as NOW() or RAND()
- If statements use an autoincrementing column, or depend on the existing data, then the queries must be executed in exactly the same order on each replica.
- Statements that have side effects (e.g., triggers, stored procedures, user-defined functions) may result in different side effects occurring on each replica.
Write-ahead log (WAL) shipping
The log is an append-only all written by the leader to its followers. It not send SQL query statement, it builds a copy of the exact same data structures as found on the leader. This used in PostgreSQL and Oracle.
The disadvantage of this approach makes replication closely coupled to the storage engine. If the database changes its storage format from one version to another, it is typically not possible to run different versions of the database software on the leader and the followers. Then, upgrades require downtime.
Logical (row-based) log replication
Another way to decouple from the storage engine. Is to send the data as rows (records) from the leader to the followers. For delete/update, just use the row identifier to be deleted/updated.
Trigger-based replication
Is the more flexible way to do replication by application code not a database system.
Problems with Replication Lag
Leader-based replication handles all writes to go through Leader and read queries go to any replica. So, its more suits to serve read-only requests. Also, it works asynchronous
Also, if an application reads from an asynchronous follower, it may see outdated information if the follower has fallen behind.
Eventual consistency is when you stop writing to the database and wait a while until the followers will eventually catch up and become consistent.
There are three problems that maybe occur when there is a replication lag.
Reading your own writes
The problem: When user writes the data to leader, it read it from followers. In async followers, it may not have reached the replica yet.
In situation, there is read-after-write consistency which guarantee that if user reload the page, it always see any updates they summitted byself.
How to implement it?
- When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower. Like user profile information on a social network is normally only editable by the owner of the profile. So always read the user’s own profile from the leader.
-
If most things in the app are editable by the user, then above approach won’t work. Another way is estimate one minute to the leader after last update, then after that read from followers.
- The problem here is the last update timestamp is associated with client device, so if there is multiple device, then cannot read from the leader at the same time, just who made the write will.
Monotonic Reads
The problem: Occur when reading from asynchronous followers is that it’s possible for a user to see things moving backward in time. Like the following diagram shows when two replica (one with little lag and other with greater lag) who read the same query from replica and when refresh didn’t read it. This scenario happens when a user refreshes a web page, it routed to random followers.
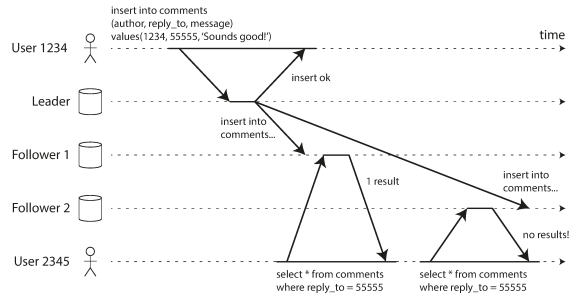
Monotonic reads guarantee that doesn’t happen by making all user queries to the same replica (to make that we hash userId with replica). if that replica fails, the user’s queries will need to be rerouted to another replica.
This mechanism is called Sticky session which each user always makes their reads from the same replica.
Consistent Prefix reads
The problem: If there is disorder of sequence of writes (if the data is sharded/partitioned)
For example, if there dialog between two person like this.
- Mr. Poons: How far into the future can you see, Mrs. Cake?
- Mrs. Cake: About ten seconds usually, Mr. Poons.
And third follower see that in disorder
- Mrs. Cake: About ten seconds usually, Mr. Poons.
- Mr. Poons: How far into the future can you see, Mrs. Cake?
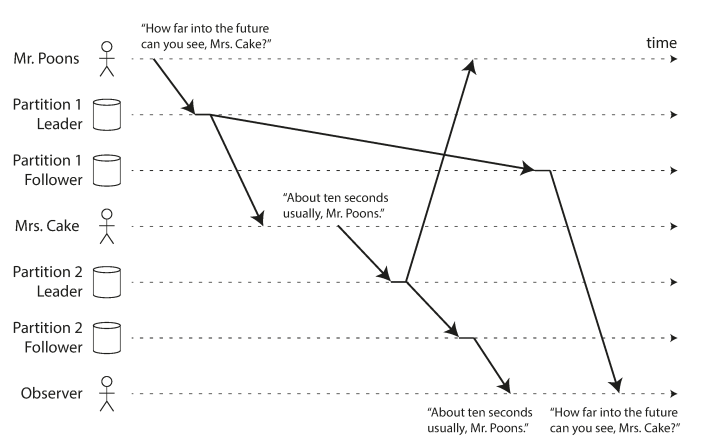
To solve this problem, make sure that casually related writes are written to the same partition, and are written in the same order.
Multi-Leader Replication
Instead of one leader to handle all writes, there is another approach for multi-leader replication. When a leader process a write, it must forward that change to all other followers.
Use Cases
-
Multi Datacenter: With a normal leader-based replication setup, the leader has to be in one of the datacenters, and all writes must go through that datacenter. In multi-leader configuration, you can have a leader in each datacenter.
Some databases support multi-leader configurations by default, but it is also often implemented with external tools, such as Tungsten Replicator for MySQL, BDR for PostgreSQL, and GoldenGate for Oracle.
The big issue in this approach is the same data may be concurrently modified in two different datacenters, and those write conflicts must be resolved.

- Clients with offline operation: every device has a local database that acts as a leader (it accepts write requests), and there is an asynchronous multi-leader replication process (sync) between the replicas of your calendar on all of your devices. The replication lag may be hours or even days, depending on when you have internet access available.
- Collaborative editing: When one user edits a document, the changes are instantly applied to their local replica and asynchronously replicated to the server and any other users who are editing the same document.
Handling Write Conflicts
Example: User 1 changes the title of the page from A to B, and user 2 changes the title from A to C at the same time. Each user’s change is successfully applied to their local leader. However, when the changes are asynchronously replicated, a conflict is detected.
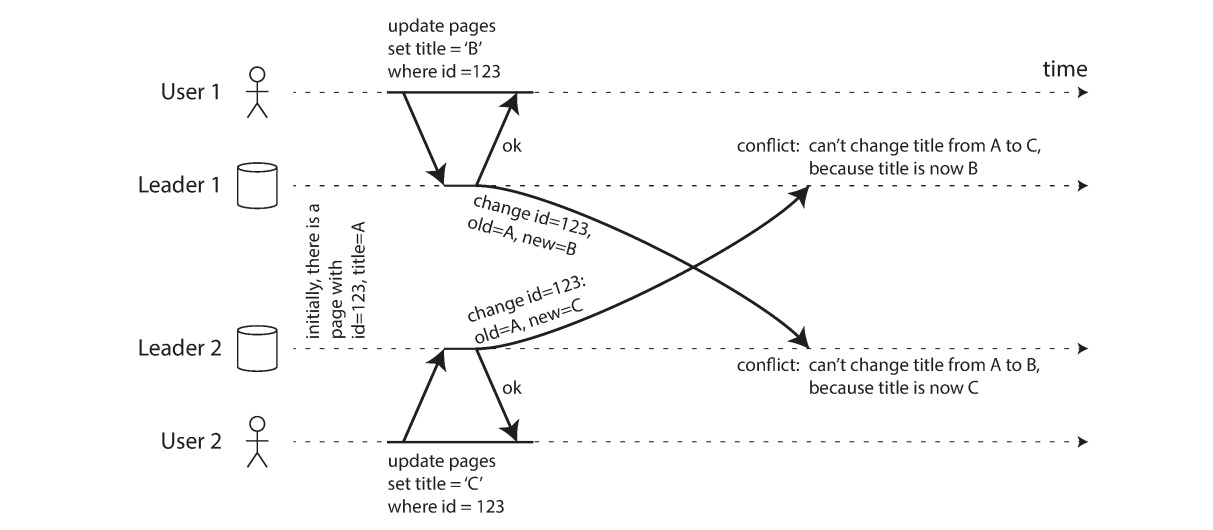
Avoid Conflict
By ensuring all writes go through the same leader. For example a user can edit their own data, you can ensure that requests from a particular user are always routed to the same datacenter and use the leader in that datacenter for reading and writing.
Converging toward a consistent state
Give each write a unique ID (e.g., a timestamp, a long random number, a UUID, or a hash of the key and value), pick the write with the highest ID as the winner, and throw away the other writes. If a timestamp is used, this technique is known as last write wins (LWW)
Custom conflict resolution logic
Most multi-leader replication tools let you write conflict resolution logic using application code.
- On Write: use conflict handler as background process and it must execute quickly.
- On Read: Like Github pull request conflicts, it shows multiple versions of the data are returned to the application. The application may prompt the user or automatically resolve the conflict, and write the result back to the database.
Multi-Leader Replication Topologies
This describes the communication paths between the leaders writes. If you have two leaders, leader 1 must send all of its writes to leader 2, and vice versa.
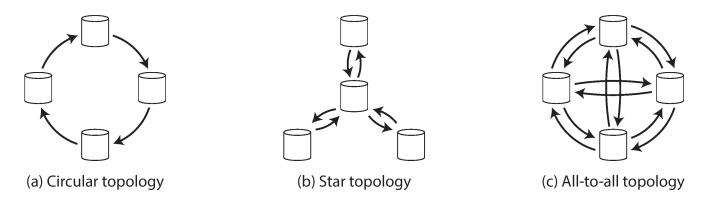
- Circular topology: each node receives writes from one node and forwards those writes (plus any writes of its own) to one other node.
- Star topology: one centered root node forwards writes to all of the other nodes.
- All-to-all topology: each node sends all writes to all nodes
The most general topology is all-to-all. MySQL by default supports circular topology. A problem with circular and star topologies is that if just one node fails.
Leaderless Replication
When our system is write-intensive, leader(s) may act as a bottleneck, that’s when leader-less replication comes in handy, also known as Dynamo-style (introduced by Amazon Dynamo internally , Not DynamoDB). The clients send their writes and reads to several replicas in parallel.
In some leaderless implementations, the client directly sends its writes to several replicas, while in others, a coordinator node does this on behalf of the client.
When a Node Is Down, the client depend on received number of ok responses to determine if write successfully or not. When read, the client sends several nodes in parallel (you may get different responses) so it depends on most updated value attached with version number.
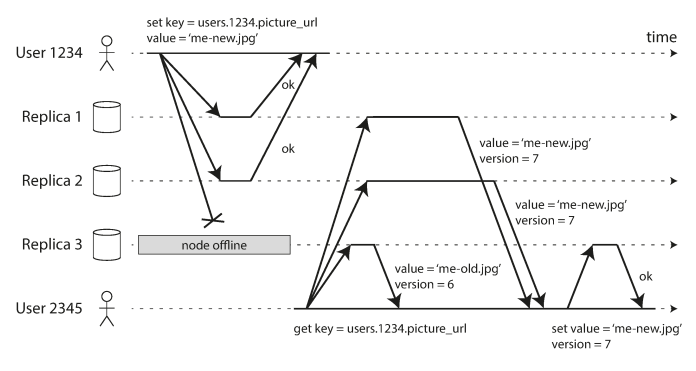
When the offline node comes back it uses Read repair and anti-entropy processes to catch up the updated values.
- Read repair: when a client makes a read from several nodes in parallel, it can detect any stale responses.
- Anti-entropy: a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another.
Quorums for reading and writing
If there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read. (In our example, n = 3, w = 2, r = 2.) As long as w + r > n, we expect to get an up-to-date value when reading, because at least one of the r nodes we’re reading from must be up to date. Reads and writes that obey these r and w values are called quorum reads and writes.
The numbers of replicas to read from (r), and to write to (w) should be configured to follow the quorums formula: w + r > n, where (n) is the number of replicas. Smaller values of w or r results in more stale read values, but provides lower latency and higher availability.
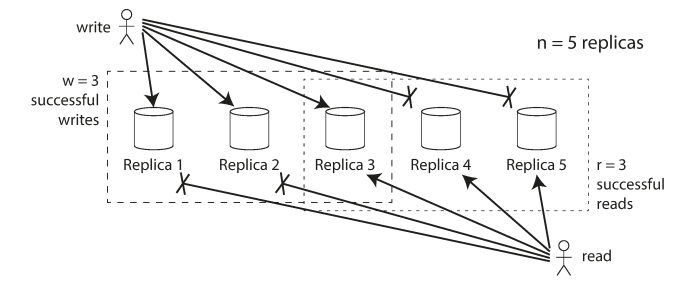
If w + r > n, at least one of the r replicas you read from must have seen the most recent successful write.
If two writes occur concurrently, it is not clear which one happened first. In this case, the only safe solution is to merge the concurrent writes.
Quorums appear to guarantee that a read returns the latest written value, in practice it is not so simple. Dynamo-style databases are generally optimized for use cases that can tolerate eventual consistency.
Sloppy Quorums
This happen when w or r nodes are unavailable, sloppy quorums allowing write operations to be considered successful even if they are acknowledged by fewer replicas than the traditional quorum. For example, if the system has three replicas, a sloppy quorum could be defined as just one replica. This make the system temporally inconsistent until to be eventually consist in the background.
Sloppy quorums are particularly useful for increasing write availability (more durability): as long as any w nodes are available, the database can accept writes.
In Riak DB they are enabled by default, and in Cassandra and Voldemort they are disabled by default.