Designing Data Intensive Applications Notes: Ch.4 Encoding and Evolution
Mohamed Kassem | November 02, 2023

Continuing our series for “Designing Data-Intensive Applications” book.
In this article, we will walkthrough the second chapter of this book Chapter.4 Encoding and Evolution.
Table of content
Changes to an application’s features also requires a change to data that it stores: perhaps a new field or record type needs to be captured (also, changes on Database schema).
In a large application, and this application is deployed in multiple servers, the code changes often cannot happen instantaneously (at no time):
- With server-side applications you may want to perform a rolling upgrade which new version to a few nodes/services at a time.
- With client-side applications you’re at the mercy of the user, who may not install the update for some time.
So, this will cause a compatibility issue whether between client/server or between the services (in the world of microservices/SOA architecture) or even producers/consumers different version.
To solve this issue, your system must support the two types of data compatibility:
-
Backward compatibility
- Newer code can read data that was written by older code (for example, you can open docx files written by Office 2010 with Office 2019).
- This is not a problem, because New code already knows the format old data, so it can handle it.
-
Forward compatibility
- Older code can read data that was written by newer code (for example, your mobile app is no updated with the new version of API).
- Can be tricky in real world, because it requires older code to ignore additions made by a newer version of the code. Take only needed/matters.
Data Representation
Programs usually work with data in (at least) two different representations:
- In Memory: objects, structs, lists, arrays, hash tables, trees, an so on. These data structures are optimized for efficient access and manipulation by the CPU (typically using pointers).
- Persisted: In file or network or IPC. you have to encode it as some kind of self-contained sequence of bytes which we call data format. Since a pointer wouldn’t make sense to any other process.
Thus, we need some kind of translation between the two representations. The translation from the in-memory representation to a byte sequence is called encoding or serialization, and the reverse operation called decoding or deserialization.
Schema
Which is a collection of fields, each one have Name and datatype.
-
Schema on Read: The code infers the schema while reading.
- Example: Document Databases like MongoDB
-
Schema on Write: the code enforce the schema while writing.
-
Example: Relational Databases like MySQL, Postgres
Formats for Encoding Data
-
Like JSON, XML, and Binary Variants. This formats is standard encoding between any programming language.
JSON
JSON’s popularity is mainly due to its built-in support in web browsers and human-readable.
Support for Unicode character strings (human readable text), but they don’t support binary strings (sequences of bytes without a character encoding)
Support backward and forward compatibility
the following format we will use it in other different formats
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}XML
XML is often criticized for being too verbose and unnecessarily complicated
Support for Unicode character strings (human readable text), but they don’t support binary strings (sequences of bytes without a character encoding)
Support backward and forward compatibility:
BSON
Binary representation of JSON-like documents.
Designed for efficient storage and retrieval of documents in MongoDB (a NoSQL database).
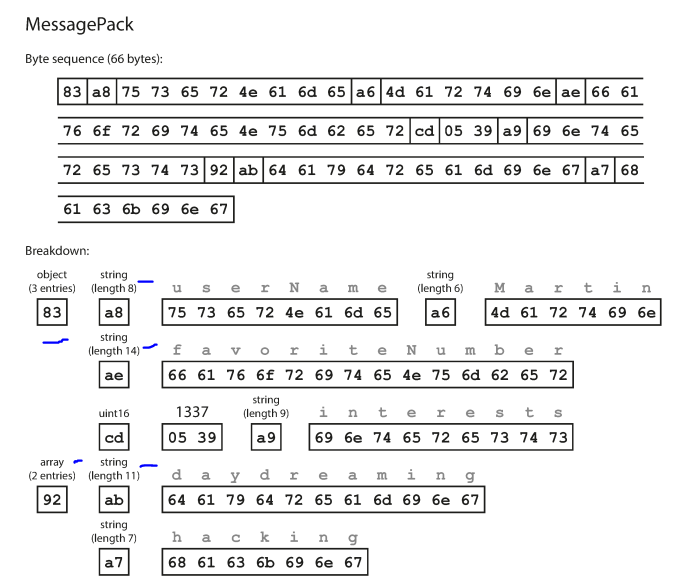
MessagePack
Doesn’t support backward and forward compatibility.
Thrift and Protocol Buffer
Protocol Buffer Developed at Google while Thrift Developed at Facebook
Both Support backward and forward compatibility
Both Require a schema for any data that is encoded
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}Thrift has two different encoding format BinaryProtocol and CompactProtocol
BinaryProtocol
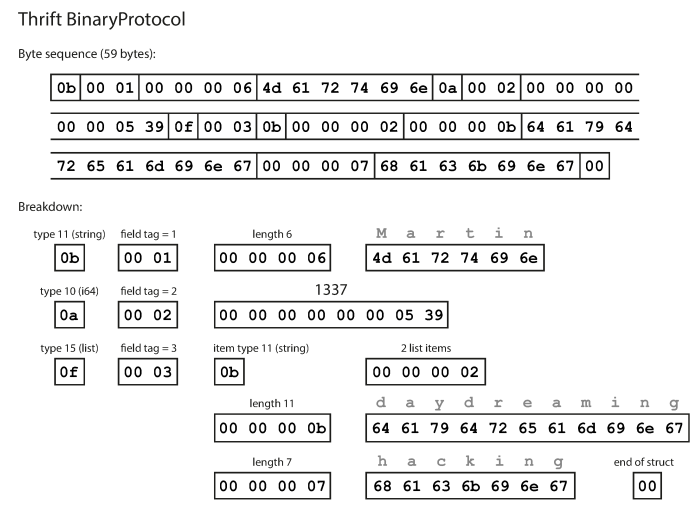
The difference between this format and above format (Message Pack) is that there are no field names (userName, favoriteNumber, interests). Instead, the encoded data contains field tags, which are numbers (1, 2, and 3). Those are the numbers that appear in the schema definition. Field tags are like aliases for fields.
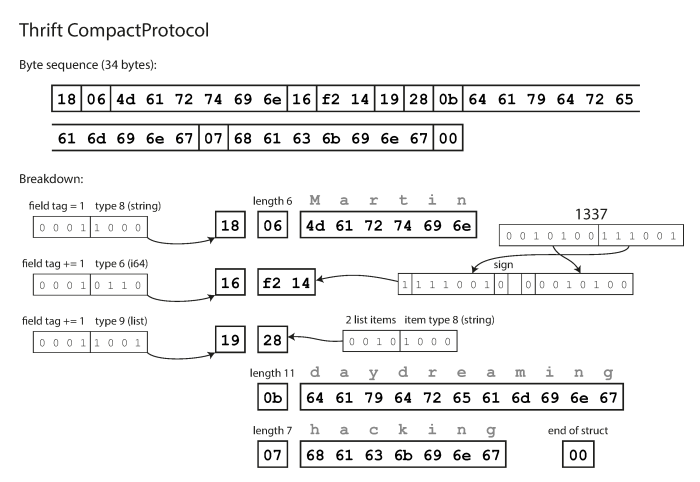
CompactProtocol
Like BinaryProtocol but it just packs the same information into only 34 bytes by merging the field type and tag number into a single byte. Rather than using a full eight bytes for the number 1337.
ProtocolBuffers
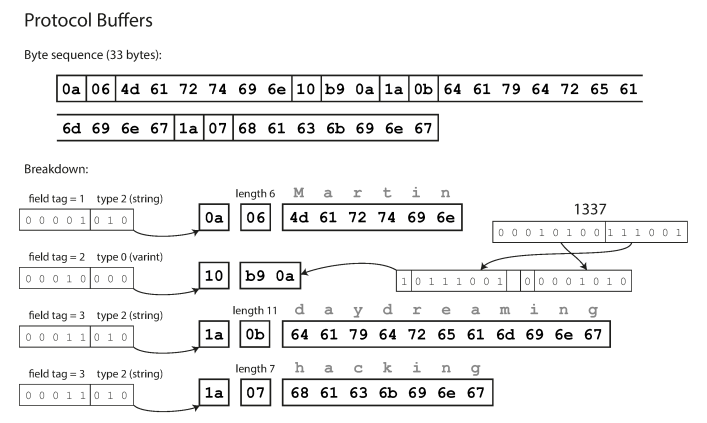
How Thrift and Protocol Buffers handle schema changes while keeping backward and forward compatibility ?
It depends on the tag field, If a field value is not set, it is simply deleted from the encoded record.
In Forward compatibility, If old code (which doesn’t know about the new tag numbers you added) tries to read data written by new code, including a new field with a tag number it doesn’t recognize and ignore that field. just read what needed data.
In backward compatibility, As long as each field has a unique tag number, new code can always read old data, because the tag numbers still have the same meaning. The only detail is that if you add a new field, you cannot make it required. So every field you add after the initial deployment of the schema must be optional or have a default value
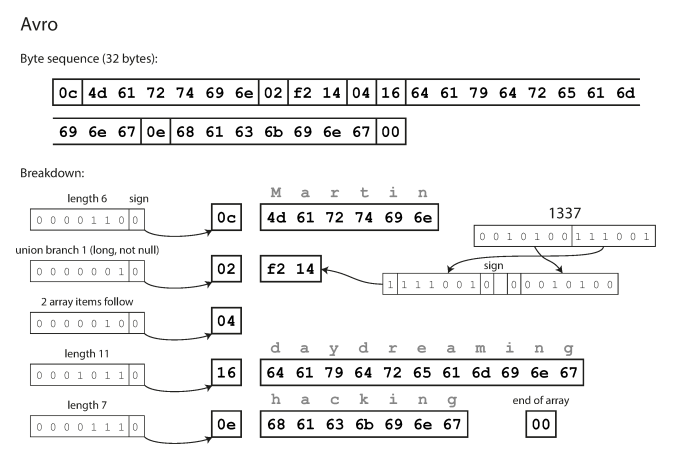
Avro
It was started in 2009 as a subproject of Hadoop.
Support backward and forward compatibility
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}The main difference that Avro don’t depend on field tag like previous formats. and there is no nothing to identify fields or their datatypes.
The binary encoding is depends on the order that they appear in the schema and use the schema to tell you the datatype of each field.
How Avro handle schema changes while keeping backward and forward compatibility?
As we discussed above about reader schema and writer schema. Avro just resolves the differences between writer’s schema and the reader’s schema.
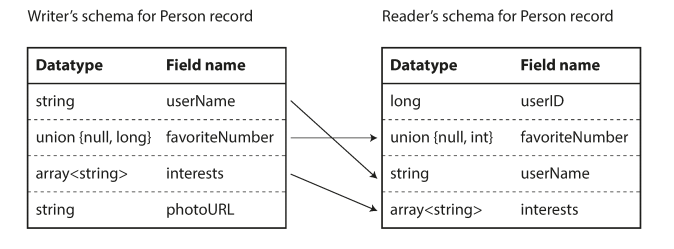
forward compatibility means that you can have a new version of the schema as writer and an old version of the schema as reader. Conversely, backward compatibility means that you can have a new version of the schema as reader and an old version as writer.
Dataflows
There are three ways of dataflows, through databases, service, or async message passing.
Dataflow through databases
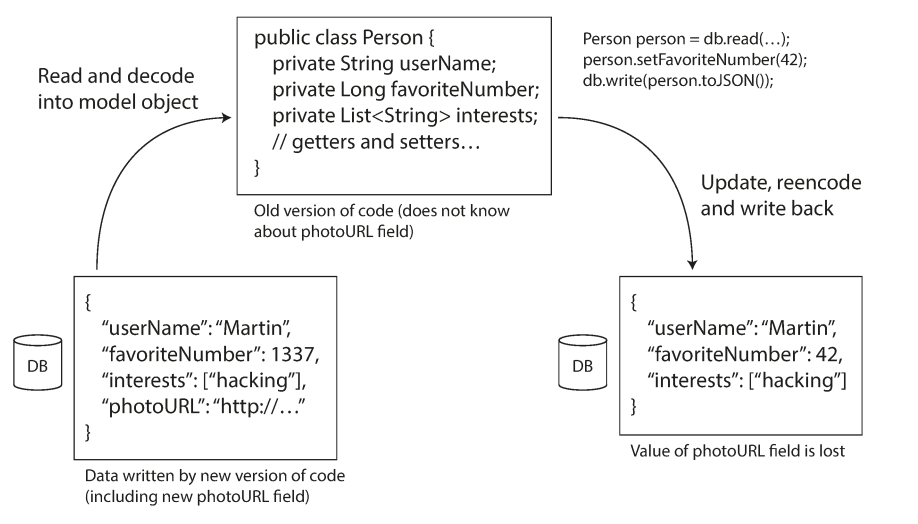
When doing rolling upgrade for your database, database may be written by a newer version of the code, and subsequently read by an older version of the code that is still running. Thus, forward compatibility is also often required for databases.
The following example shows when an older version of the application updates data previously written by a newer version of the application, data may be lost if you’re not careful.
Dataflow through Services (REST and RPC)
Communication is done over network, this called web services which talking to the service over http protocol.
- Client(web browsers or mobile or desktop)/server
- A server can itself be a client to another service (for example, a web app server acts as client to a database)
- Service-Oriented Architecture (SOA) and Microservices architecture
Three popular approaches to web services: REST, SOAP, and RPC.
REST is not a protocol, but rather a design philosophy that builds upon the principles of HTTP Like cache control, authentication, and content type negotiation. Support OpenAPI (Swagger) to produce documentation. There is no any code generation or software installation to debug it. REST seems to be the predominant style for public APIs
SOAP is an XML-based protocol for making network API requests that also done over HTTP. Has its own features like WSDL for code generation. REST is commonly used compared to SOAP.
Remote Procedure Call (RPC) is a dataflow model that tries to make a request to a remote service looks like a local function call. However, it is flawed due to the difference between network call and local call:
- Network call is unpredictable, client would have to retry failed requests for example
- Network calls can return without a result due to a time out
- Retrying might cause an action to be performed twice (unless idempotence is used)
- Network latency is wildly variable
- Calling local function with memory reference might be hard to translate to a network call
Thrift and Avro come with RPC support included. gRPC is an RPC implementation using Protocol Buffers.
RPC protocols with a binary encoding format can achieve better performance than something generic like JSON over REST.
The main focus of RPC frameworks is on requests between services owned by the same organization, typically within the same datacenter.
For RPC, we can make a simplifying assumption in the case of dataflow through services: it is reasonable to assume that all the servers will be updated first, and all the clients second. Thus, you only need backward compatibility on requests, and forward compatibility on responses.
Thrift, gRPC, Avro RPC, SOAP, REST all support forward compatibility and backward compatibility
Dataflow through async message passing.
Here, the client request(called message) send to intermediary called message broker or queue to store the message temporarily.
- Improves system reliability when the service is unavailable
- Message cannot be lost
- Distributed and concurrency sends message to multiple nodes
- Decouple the sender from the recipient
Popular message brokers like RabbitMQ, ActiveMQ, Kafka, NATS
Client sends a message to a named queue or topic, and the broker ensures that the message is delivered to one or more consumers of or subscribers to that queue or topic. There can be many producers and many consumers on the same topic.
In message format, you can use any encoding format. If the encoding is backward and forward compatible.